

 English
English العربی
العربی Swedish
Swedish François
François

همانطور که در مطلب «لیستی از کلمات بازدارنده در زبان فارسی - Stop Words in Persian» گفته بودم، میخواهم بخشی از یکی از درسهای جالب دانشجویان رشته کامپیوتر (در دانشگاه علمی-کاربردی، رشته فناوری، مقطع کارشناسی) به نام «نمایهسازی» را اینجا توضیح دهم.
نمایهسازی همان کلمه Indexing است که موتورهای جستجو مانند گوگل از آن برای یافتن صفحات مرتبط با عبارتی که جستجو کردهاید از بین ۶۰ تریلیون صفحه روی اینترنت، استفاده میکنند. (شما وقتی یک عبارت را روی هارد خود جستجو میکنید میبینید حداقل چند ثانیه و گاهی چند دقیقه طول میکشد که بگوید این عبارت روی هاردی که در نیممتری شما است وجود دارد یا خیر. اما فقط کافیست یک کلمه را در گوگل جستجو کنید تا میلیونها نتیجه را در کمتر از نیمثانیه به شما نشان دهد! این عظمت و اهمیت نمایهسازی را میرساند! مثال دیگر برای نمایه، نمایههای انتهای کتاب است. قدیمترها وقتی میخواستند ببینند در چه آیاتی یک کلمه خاص بیان شده، چطور میفهمیدند؟ از نمایهی قرآن استفاده میکردند. یک خاطره: یادم هست که من اول راهنمایی بودم که یکی از معلمها یکی از آنها با نام «المُعجَم المُفَهرَس» را معرفی کرد! همان روز راه افتادم در بازار، کلی گشتم اما هیچ کس نداشت... و جالب است که نهایتاً مدیر مدرسهمان در همین حین بنده را دید و پرسید در بازار چه میکنی؟... خلاصه دستم را گرفت و برد پیش یک پیرمرد کتابفروش که کسی فکرش را نمیکرد که بین کتابهای محدودش این را هم داشته باشد اما داشت و خریدم و هنوز هم استفاده میکنم)
به هر حال، یکی از کاربردهای نمایهسازی، یافتن مطالب مرتبط با یک موضوع در دیتابیس است. (دقیقاً مانند موتور جستجو که صفحات مرتبط با عبارتی که جستجو میکنید را مییابد...)
روشهای مختلفی برای یافتن مطالب مرتبط وجود دارد. مثلاً یک راه ساده که اکثر CMSها و افزونههای مربوط به مطالب مرتبط استفاده میکنند این است که شما هنگام افزودن مطلب، آنرا نمایهگذاری کنید یعنی بگویید که این مطلب در زیرمجموعهی چه موضوعی قرار دارد؟ مثلاً در مورد «نجوم» است؟ یا یک «مطلب فرهنگی» است؟ ... بعد، بیایید در زیر هر مطلب، مثلاً پنج مطلب آخر که موضوع مشابه با این مطلب را دارند لیست کنید.
مثلاً دیدم که سایت p30download از این روش استفاده میکند:
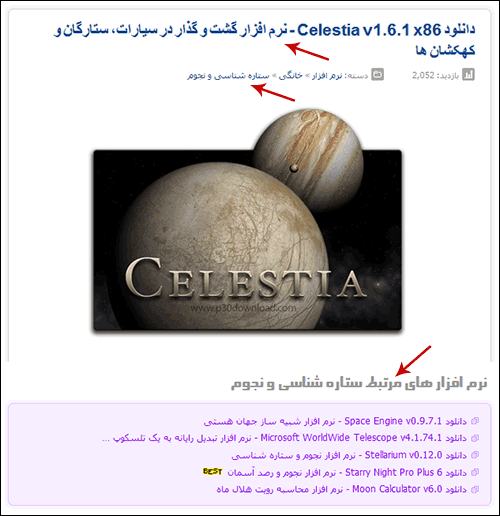
این روش، روش خوبی است و ممکن است حتی گاهی اوقات برای سایتها بهترین حالت باشد، اما نقاط ضعفی دارد؛ از جمله:
- باید از همان ابتدا که مقالات را مینوشتید به فکر برچسبگذاری یا انتخاب موضوع میبودید. یعنی اگر از اول موضوعبندی نکرده باشید یا بعداً بخواهید موضوعات را خاصتر کنید (مثلاً به جای بحث کلی نجوم، بخواهید مطالب مربوط به خورشید را جدا کنید) باید همه مطالب را ویرایش کنید و موضوع جدید را تعیین کنید و طبیعتاً این کار وقتگیر است.
- مطالبی که لیست میشوند، فقط از یک لحاظ با هم مرتبط هستند: موضوع! مثلاً این تصویر را ببینید:

در حالی که اسم این مطلب «بازی میکی فوق العاده...» بوده اما هیچ کدام از مطالب مرتبط که لیست شده هیچ ربطی به میکی ندارد! تنها اشتراک آنها بازی بودن آنهاست.
به هر حال، روش دقیقتر و علمیتری نیز وجود دارد اما ابتدا نکاتی در مورد این روش:
- این روش نسبتاً پیچیده است و پیادهسازی آن زحمت بیشتری میطلبد.
- در زبانهای مختلف بستگی به کلمات کلیدی و غیرکلیدی آن زبان دارد. یعنی نمیشود یک افزونه توسط افراد خارجی نوشته شود و در فارسی درست عمل کند! برای هر زبانی دیتابیسهای خاص آن زبان نیاز است.
- در تعداد مطلب کم ممکن است هیچ نتیجهای را برنگرداند اما در تعداد مطلب زیاد احتمالاً بهتر عمل میکند.
- برای دقیقتر شدن الگوریتم نیاز به الگوریتمهای دیگری نیز هست و در مجموع شما باید یک «گوگل» را طراحی کنید تا دقیقتر عمل کند!! مثلاً شاید لازم باشد شما مانند گوگل که تازه بعد از ۲۰ سال این کار را کرده، به الگوریتمتان بفهمانید که «فتوشاپ» همان Photoshop است وگرنه اگر در عنوان یک مطلب «فتوشاپ» نوشته شده باشد، مطالب مرتبطی که در عنوانشان Photoshop نوشته شده یافت نمیشوند!
مزایای این روش، برعکس معایب روش قبلی است؛ یعنی:
- نیازی نیست نگران برچسبها و موضوعاتی که هنگام درج مطلب انتخاب کردهاید باشید. الگوریتم خودش مقالات مرتبط را پیدا میکند.
- مطالبی که یافت میشوند احتمالاً از لحاظهای مختلف با مطلب فعلی ارتباط خواهند داشت.
و اما الگوریتم:
۱- ابتدا باید عنوان مطلب فعلی را با معیار فاصله (Space) تکهتکه کنید. مثلاً فرض کنید یک مطلب داریم با عنوان «آموزش ترمیم عکس قدیمی در فتوشاپ». باید با توابعی که در اختیار دارید (مانند تابع explode در زبان PHP و Split در زبانهای داتنت) عنوان را با معیار فاصله در اصطلاح منفجر کنید تا هر کلمه در یک خانه از یک آرایه قرار گیرد. در انتهای این مرحله یک آرایه خواهید داشت که در هر خانه یک کلمه از کلمات عنوان مطلب وجود دارد.
۲- باید کلمات غیرکلیدی از آرایه حذف شوند و نهایتاً فقط کلمات کلیدی باقی بمانند. برای اینکه این کار دقیقتر صورت گیرد شما به سه مجموعه داده (دیتابیس) نیاز دارید:
-- دیتابیسی به نام Stop Words یا کلمات بازدارنده: در مورد این دیتابیس در مطلب «لیستی از کلمات بازدارنده در زبان فارسی - Stop Words in Persian» توضیح دادم و لیستی از مهمترین کلمات را قرار دادم. به طور خلاصه، حروف اضافه (مانند «به»، «از» و ...) و حروف ربط (مانند «که»، «پس» و ...) و ضمایر (مانند «من»، ««او» و...) جزء این لیست خواهند بود. افعال عمومی مثل «باش، کن و ...» هم هستند که البته بحث صرف کردن افعال خودش یک مبحث مفصل است. بنابراین در حالت ساده، اگر خواستید میتوانید با توابع مربوط به عبارات منظم (مثل preg_match در PHP) هر کلمهای که شامل آن افعال بود را حذف کنید و یا مثل من آنها را فعلاً در این مرحله حذف نکنید.
-- دیتابیسی به نام Go List یا Keywords یا کلمات کلیدی: این دیتابیس حاوی کلماتی خواهد بود که در یک زمینه خاص، کلمه کلیدی هستند. مثلاً اگر مطالب شما کامپیوتری است، کلمات کلیدی شما با کسی که سایت خبری سیاسی دارد متفاوت است. شما باید هر کلمهای که در این دیتابیس نیست را هم حذف کنید. به طور مثال در مطلب «آموزش ترمیم عکس قدیمی در فتوشاپ» کلماتی مثل «ترمیم» و «قدیمی» کلمه کلیدی نیستند و باید با توجه به دیتابیس کلمات کلیدی رشته کامپیوتر حذف شوند. (درد دل: متأسفانه طبق جستجوهای من، ما هنوز دیتابیسهایی که کلمات کلیدی هر زبان را جدا کرده باشد نداریم. اینقدر پروژه و کارآموزی در دوران کاردانی و کارشناسی به خاطر سخت بودن موضوع از روی اینترنت کپی میشوند و تحویل استاد داده میشوند اما آن استاد محترم نمیآید یک موضوع مثل این موضوعات ارائه کند که هم برای یک زبان در طول تاریخ خیر داشته باشد و هم آن دانشجو بداند که یک کار مفید انجام داده و انرژی بگیرد... ما دکترهایی داریم که رساله دکترای خود را روی جمعآوری بسامد کلمات فارسی قرار دادهاند. این قضیه نه تنها برای آن دکتر کسر شأن نیست، بلکه یک افتخار هم هست. حالا ما فکر میکنیم دانشجوی کاردانی و کارشناسی ما باید حتماً روی یک موضوع کار کند که در کره زمین کار نشده باشد یا حتی به عقل زمینیها نرسیده باشد! گاهی میبینم اساتید موضوعات مسخرهای به دانشجویان مظلوم میدهند که آن دانشجو اصلاً نمیفهمد این موضوع یعنی چی!؟ و نهایتاً بعد از کلی جستجو و تحقیق، میرود پول میدهد بیرون برایش انجام دهند! ای کاش یک روز اساتید ما موضوعات پروژه و کارآموزی را مثلاً جمع آوری کلمات کلیدی رشته دانشجو قرار دهند. مثلاً کلمات کلیدی رشته کامپیوتر. کلمات کلیدی رشته عمران و ... هر چقدر که در توان دانشجو است این دیتابیس را کامل کند و دانشجوی ترمهای بعد، آنرا کاملتر و بهروزتر کند... این دیتابیسها در یک وبلاگ برای استفادهی عموم به کار گرفته شوند. من خودم چند دانشجو را برای رشته کامپیوتر به کار گرفتهام و قرار است بیشتر در این زمینه کار کنیم...)
به هر حال، شما برای کار دقیقتر به این دیتابیس نیاز دارید اما اگر گیر نیامد، مجبورید این مرحله را انجام ندهید. (مطالبی که یافت میشوند طبیعتاً کمی نامرتبطتر خواهند بود)
-- دیتابیسی به نام Semi-Stop Words یا کلمات نیمهبازدارنده: کلماتی که جزء دیتابیس کلمات بازدارنده و کلمات کلیدی نباشند، کلمات نیمهبازدارنده به حساب میآیند و آنها نیز باید حذف شوند. مانند «ترمیم» و «قدیمی» در عنوان مثالی ما. در حقیقت شما به یکی از دیتابیسهای Go List و Semi-Stop Words نیاز دارید و دومی میتواند از روی تفریق به دست آید. یعنی بعد از اینکه شما کلمات بازدارنده را حذف کردید و از روی دیتابیس کلمات کلیدی، کلمات کلیدی را مشخص کردید، هر چه باقی میماند میشود کلمات نیمهبازدارنده که باید آنها نیز حذف شوند.
۳- در انتهای مرحهی ۲ شما یک آرایه دارید که در آن کلمات کلیدی که در عنوان مطلب فعلی بوده، قرار دارد. مثلاً در عنوان فرضی ما کلمه «در» با استفاده از Stop Words حذف میشود، کلمات «ترمیم» و «قدیمی» هم با توجه به دیتابیس Semi-Stop Words حذف میشوند و نهایتاً کلمات «آموزش» و «عکس» و «فتوشاپ» در آرایه میماند.
حالا باید این کلمات را با استفاده از عملگر LIKE، جدا-جدا در دیتابیسِ مقالات، جستجو کنید. (مثلاً یک بار «آموزش» را... یک بار «عکس» را...) نتیجه این جستجو لیستی از مقالاتی خواهد بود که مرتبط با هر کلمه هستند. مثلاً چیزی شبیه به تصویر زیر خواهیم داشت:
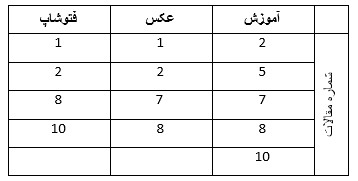
حالا فرض کنید قرار است نهایتاً ۵ مقاله مرتبط را لیست کنیم. این سؤال پیش میآید که کدام مقالات را بالاتر بیاوریم. (دقیقاً همان قضیهای که گوگل هنگام یافتن هزاران نتیجه در قبال جستجوی شما نیاز دارد که فکری در موردش کند. یعنی کدام سایت را بالاتر بیاورد؟)
باز، همین موضوع خودش کلی بحث دارد. مثلاً گوگل برای مرتب کردن این لیست از ۲۰۰ معیار مختلف کمک میگیرد!!!
اما فعلاً ما اولین گامی که گوگل برمیدارد را برمیداریم: گوگل ابتدا مقالاتی را میآورد که تعداد بیشتری از کلمات کلیدیای که در مرحله قبل به دست آمد را شامل شوند. مثلاً در تصویر بالا، مقالات شماره 2 و 8 هر سه کلمه را شامل میشوند، پس ابتدای لیست میآیند. سپس از راست به چپ (و اگر زبان جستجو انگلیسی بود، از چپ به راست) اولویت کلمات را بالاتر فرض میکنیم و هر مقالهای که تعداد بیشتری کلمه کلیدی را دارد لیست میکنیم. مثلاً مقاله شماره 7 که کلمات «آموزش» و «عکس» را دارد در جایگاه بعدی قرار میگیرد و مقاله شماره 10 در جایگاه بعد و در نهایت مقاله شماره 5 که فقط یک کلمه کلیدی را دارد در لیست قرار میگیرد:
2
8
7
10
5
من شکل سادهای از این الگوریتم را در بخش مقالات سایت پیادهسازی کردم:
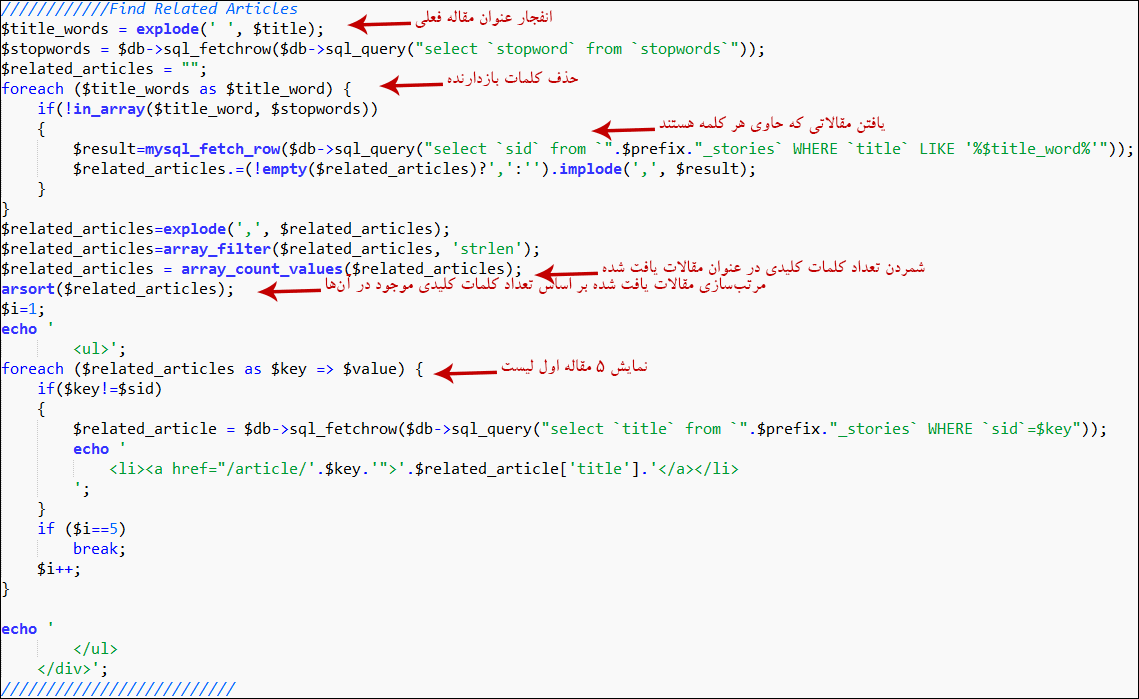
برای دیدن تصویر در ابعاد واقعی روی آن کلیک کنید...
با توجه به اینکه فعلاً دیتابیس کلمات کلیدی رشته کامپیوتر را ندارم الگوریتم در اکثر موارد شاید خیلی دقیق عمل نکند و نیاز به بهبود دارد اما برای شروع بد نیست... مثلاً به انتهای برخی از مقالات (بخش مطالب مرتبط) دقت کنید: (مثلاً اینجا و اینجا ... عدد انتهای آدرس را میتوانید به هر عددی تغییر دهید و بررسی کنید)
در این الگوریتم موارد زیر باید مد نظر قرار گیرد:
- مشکل عمدهی زبان فارسی: حرف «ی» و «ک» فارسی و «ي» و «ك» عربی! ممکن است مقالات شما با ي عربی (که دو نقطه زیر آن دارد) نوشته شده باشد و مقاله فعلی با ی فارسی باشد و اینها کلاً با هم فرق میکنند! پس باید عنوان مقالات دیتابیس یکدست شوند...
- علاماتی مانند : ، ! () و ... باید حذف شوند. شاید بهتر باشد کلمات یک کاراکتری را از آرایه حذف کنید.
- کلماتی مانند «می» یا «ها» و «اند» و ... کار را خیلی خراب میکنند. اینها هم باید از آرایه حذف شوند.
- نکات مختلفی وجود دارد که در حین پیادهسازی به آنها برمیخورید. احتمالاً به مرور این مقاله کاملتر شود.
موفق باشید؛
حمید رضا نیرومند





















 Hamid:
Hamid: