

 English
English العربی
العربی Swedish
Swedish François
François

در مطلب قبل (یعنی الگوریتمِ پیدا کردن مطالب مرتبط با یک مقاله از بین صدها مقاله) در بخشی از مطلب به این موضوع اشاره کردم که برای اینکه ما مطالب مرتبط با یک مطلب را از دیتابیس پیدا کنیم، نیاز داریم که کلمات کلیدی مطلب فعلی را به دست آوریم و اشاره کردم که برای این کار نیاز به دیتابیسی داریم به نام Go List و گفتم که چنین دیتابیسی فعلاً برای رشته کامپیوتر وجود ندارد.
اما بعد از آن مطلب، دنبال راه حلی گشتم که بشود بدون داشتن هر نوع دیتابیسی (حتی اگر دیتابیس Stop Words یا کلمات بازدارنده مثل «از» و «به» و ...) را نداشته باشیم، بتوانیم کلمات کلیدی را از داخل یک متن استخراج کنیم.
دقت کنید که اگر حتی دیتابیس Go List موجود میبود، ممکن بود کلماتی که در آن دیتابیس است برای یک سایت خاص کلمه کلیدی به حساب نیاید. به طور مثال فرض کنید دیتابیس کلمات کلیدی بگوید که کلمه «چاپ» در رشته کامپیوتر یک کلمه کلیدی است اما این کلمه در سایتی مانند سایت ما واقعاً کلمه کلیدی نیست! ما اصلاً در مورد چاپ صحبت خاصی نداشتهایم! این موضوع نشان میدهد که کلمات کلیدی یک مطلب یا سایت باید از طریق خود آن مقاله یا مقالات آن سایت به دست آید.
در این مطلب قصد دارم روشی را معرفی کنم که با استفاده از آن میتوان تا حد زیادی کلمات بازدارنده (Stop Words) و کلمات نیمه بازدارنده (یا Semi-Stop Words: کلماتی مانند «ترمیم» و «قدیمی» در عنوان «آموزش ترمیم عکس قدیمی در فتوشاپ») و کلمات کلیدی (یا Go List یا Keywords: کلماتی مانند «آموزش» و «عکس» و «فتوشاپ» در عنوان «آموزش ترمیم عکس قدیمی در فتوشاپ») را از طریق مطالب سایت به دست آورد.
این روش «فراوانی وزنی» یا TF-IDF نام دارد:
TF-IDF مخفف Term Frequency - Inverse Document Frequecy و به معنی «فراوانی کلمه-عکسِ فراوانی سند» است.
در مورد این روش به خوبی در این مقاله انگلیسی و ترجمهی آن توضیح داده شده است:
در این شیوه به لغات یک وزن بر اساس فراوانی آن در سند داده می شود. در واقع این سیستم وزندهی نشان میدهد چقدر یک کلمه برای یک سند (مدرک) مهم است. این مساله کاربردهای بسیاری در بازیابی اطلاعات دارد. وزن کلمه با افزایش تعداد تکرار آن در متن افزایش مییابد، اما توسط تعداد کلمات در متن کنترل میشود، چرا که میدانیم در صورت زیاد بودن طول متن، بعضی از کلمات به طور طبیعی بیشتر از دیگران تکرار خواهند شد، اگرچه چندان اهمیتی در معنی نداشته باشند.
نتیجه محاسباتی که خواهم گفت، عددی میشود که tfidf نامیده میشود. با تغییر رنج این tfidf آن سه دیتابیس به دست خواهند آمد. به طور مثال اگر tfidf را نزدیک به 0 بگیریم، کلمات
Stop Words به دست میآیند. اگر این عدد را نزدیکترین مقدار به بالاترین عددی که به دست میآید بگیریم، کلمات کلیدی به دست میآید و بقیه هم که کلمات نیمه-بازدارنده میشوند.
tfidf چطور به دست میآید؟
برای به دست آوردن این عدد در مورد یک کلمه، به مواد زیر نیاز دارید:
Tf : برای به دست آوردن Tf مربوط به یک کلمه در یک دیتابیس باید ببینید کدام سندها حاوی آن کلمه هستند و در هر سند آن کلمه چند بار تکرار شده است؟ ماکزیمم تعدادی که این کلمه در یک سند تکرار شده را Tf بگیرید. به مثال زیر دقت کنید:
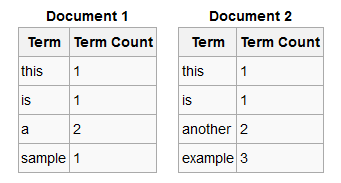
در این مثال دو سند داریم. که تعداد تکرار کلمات آن سند مقابل هر کلمه نوشته شده. اگر شما Tf مربوط به کلمه example را بخواهید، پاسخ، ۳ خواهد بود. چون این کلمه در سند دوم بیشترین تکرار را داشته که ۳ بار بوده. Tf کلمه a برابر با ۲ میشود چون ۲ بار در سند اول تکرار شده.
idf: کمی سختتر به دست میآید:
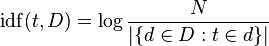
این فرمول یعنی idf به این صورت محاسبه میشود: لگاریتمِ [تعداد کل مقالات تقسیم بر (تعداد مقالاتی که شامل این کلمه میشوند+1)]
این معیار به تنهایی برای یافتن کلمات بازدارنده کافی است! فرض کنید کل مقالات شما ۱۰۰ تا باشد و کلمهی «در» در همه مقالات تکرار شده باشد. در این صورت لگاریتم ۱۰۰ تقسیم بر ۱۰۰ (یعنی لگاریتم ۱) میشود: 0
هر گاه این معیار 0 یا خیلی نزدیک به 0 شد یعنی آن کلمه جزء کلمات بازدارنده است.
tfidf: این معیار که پارامتر تصمیمگیری در مورد کلیدی بودن یا نبودن یک کلمه است از طریق ضرب دو پارامتر بالا به دست میآید:
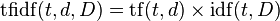
شما با کنترل tfidf میتوانید انواع کلمه (کلیدی، غیرکلیدی و بازدارنده) را به دست آورید...
دقت کنید که به جای متن مقالات میتوانید عنوان مقالات را هم ملاک قرار دهید. اما با توجه به اینکه تعداد تکرار یک کلمه در عنوان، معمولاً ۱ است پس Tf را 1 در نظر میگیریم و یعنی میتوان آنرا حذف کرد و فقط idf را ملاک قرار داد.
به طور مثال اگر ما بخواهیم مقالات مرتبط با همین مقاله (چگونه بفهمیم یک کلمه در یک سایت کلمه کلیدی است؟ [معرفی الگوریتم «فراوانی وزنی]) را از بین حدود ۱۲۰۰ مقاله سایت به دست آوریم باید این روال را طی کنیم:
- اولاً تعداد کل مقالات را به دست میآوریم. (فرض کنید ۱۲۰۰ مقاله)
- تک تک کلمات عنوان را در دیتابیس جستجو کنیم. (مثلاً کلمه «چگونه» را)
- تعداد مقالاتی که هر کلمه را شامل میشود محاسبه میکنیم. (مثلاً الان کلمه «چگونه» در ۴۲ مقاله تکرار شده و کلمه «در» در ۳۱۳ مقاله)
- لگاریتم تعداد کل مقالات تقسیم بر تعداد مقالاتی که هر کلمه تکرار شده را محاسبه میکنیم. (مثلاً در مورد کلمه «چگونه» لگاریتم ۱۲۰۰ تقسیم بر ۴۲ میشود: ۱.۴ و لگاریتم «در» میشود: 0.5)
- هر کلمهای که نتیجهاش نزدیکتر به 0 باشد یعنی کمتر کلیدی است...
این الگوریتم را در بخش «آموزشهای آفتابگردان» به کار گرفتم. در پایین آموزشها به مطالب مرتبط نگاه کنید... به نظر میرسد دقیقتر عمل میکند...
موفق باشید؛
حمید رضا نیرومند





















 صلوات:
صلوات: