

 English
English العربی
العربی Swedish
Swedish François
François

عجب درسی شد این درس «نمایهسازی» در ترمی که گذشت! چه چیزها که آموختیم و آموزش دادیم!
به هر حال، یکی از مباحثی که من نام آنرا در همه زمینهها درگیر دیدهام، بحثی است به نام «مدل پنهان مارکوف» یا Hidden Markov Model = HMM
اولین بار زمانی که داشتم پارسخوان را طراحی میکردم به آن برخوردم و در پایاننامه ارشد هم دوباره تجدید دیدار کردیم و در چند جای دیگر هم رد پایش را دیدهام اما فرصت نشده بود که بنشینم یک تحلیل اساسی روی آن داشته باشم تا اینکه گفتم برای درس نمایهسازی مطرح کنم...
مدل مخفی مارکوف چیست؟
مشکل؟
بحث را با یک جمله شروع میکنم. این جمله را بخوانید: مادر به فرزندش گفت: کرم را به من بده.
خوب، شما (ای انسان!) وقتی به «کرم» رسیدید این کلمه را چه خواندید؟ kErEm؟ درست است؟ چرا kErm یا kArAm یا kOrOm نخواندید؟
اگر بتوانید جواب سؤال من را بدهید، مدل مخفی مارکوف را درک کردهاید.
از لحاظ علمی، دلیل این بود: شما کلمه «مادر» را دیدید (یعنی فعلاً یک چیزهایی در ذهن دارید) و بعد که به کلمه «کاف را میم (کرم)» رسیدید با توجه به آنچه قبلها آموختهاید (یعنی طی سالها آموختهاید که معمولاً «مادر» kErEm را درخواست میکند) و با توجه به اینکه چند لحظه قبل کلمه «مادر» را دیده بودید، با توجه به این دانستهها، آن کلمه را kErEm خواندید... اما من به شما بگویم که: گول خوردید!!! ![]() من این جمله را از داستانی گفتم که نام طفلِ شیرخوار یک مادر، kArAm بود که این طفل چند لحظه دست دختر بزرگ خانواده بود که مادر خستگی در کند. حالا که خستگیاش را در کرد، بنابراین مادر به فرزندش گفت: کرم را به من بده... (چه جالب! حالا همان کلمه را kArAm خواندید!!)
من این جمله را از داستانی گفتم که نام طفلِ شیرخوار یک مادر، kArAm بود که این طفل چند لحظه دست دختر بزرگ خانواده بود که مادر خستگی در کند. حالا که خستگیاش را در کرد، بنابراین مادر به فرزندش گفت: کرم را به من بده... (چه جالب! حالا همان کلمه را kArAm خواندید!!)
خوب، ببینید، مشکل ما در بحث جستجو همین است! فرض کنید یک نفر در گوگل جستجو میکند: کرم ضد آفتاب. تصور کنید گوگل تصویر و مقالهی یک مشت kErm را به او نشان بدهد!!! خداوکیلی شما باشید دیگر این کلمه را جستجو میکنید؟![]()
اما خوب، گوگل (آن ماشین!) بندهی خدا از کجا بفهمد که شما منظورتان kErEm بود و نه kErm ؟
ما دقیقاً همان مشکل را در پارسخوان داشتیم و داریم! اگر کسی نوشت «کرم را به من بده» این «کاف را میم» را چه بخوانیم؟ kErEm؟ یا kErm یا kOrOm...؟ (به قول یکی از دانشجوها شاید اصلاً این جمله در یک داستان بوده که یک خانواده رفتهاند ماهیگیری و مادر به فرزندش گفته kErm را به من بده که بزنم سر قلاب و ماهی بگیرم...)
***
به طور خلاصه مدل مخفی مارکوف به همان چیزی اشاره دارد که در بالا اشاره کردم:
یعنی ما با توجه به دانستههای قبلی و با توجه به یک سری داده اولیه یا حالت آغازین، به یک حالت یا State پایانی برسیم.
یک بار دیگر:
یعنی ما با توجه به دانستههای قبلی (اینکه شما طی سالها معمولاً کلمه مادر را با kErEm دیدهاید) و با توجه به یک سری داده اولیه یا حالت آغازین (اینکه چند کلمه قبل از «کرم» کلمه «مادر» دیده شد)، به یک حالت یا State پایانی (یعنی kErEm) برسیم.
ویکیپدیا یک مقاله (بخوانید ترجمه) نسبتاً جامع در مورد مدل مخفی مارکوف دارد (البته بگذریم که آنها به جای «مخفی» میگویند «پنهان» که عربی نباشد اما برای «مدل» که انگلیسی است دنبال معادل نمیگردند!). در این مقاله یک مثال انصافاً ملموس و جالب آمده که به درک این موضوع خیلی کمک میکند. من روانترش را برایتان تعریف میکنم:
دو برادر و خواهر به نامهای آلیس و باب را در نظر بگیرید. آنها دور از هم زندگی کرده و هر روز دربارهٔ کارهای روزمرهشان با هم تلفنی صحبت میکنند. فعالیتهای باب شامل "قدم زدن در پارک"،"خرید کردن" و "تمیز کردن آپارتمان" میشود. انتخاب اینکه هر روز کدام کار را انجام دهد منحصراً بستگی به هوای همان روز دارد. آلیس اطلاع دقیقی از هوای فعلی محل زندگی باب نداشته ولی از تمایلات کلی وی آگاهاست (بنا به نوع هوا چه کاری را دوست دارد انجام دهد). بر اساس گفتههای باب در پایان روز قبل، آلیس سعی میکند هوای آن روز را حدس بزند.
در حقیقت آلیس هوا را یک زنجیره گسسته مارکوف میپندارد که دو حالت "بارانی" و "آفتابی" دارد. اما به طور مستقیم هوا را مشاهده نمیکند. بنابرین حالات هوا بر او مخفی است. در هر روز احتمال اینکه باب به "قدم زدن"،"خرید کردن" و "تمیز کردن"بپردازد بستگی به هوا داشته و دارای یک احتمال مشخص است و این احتمال را آلیس به مرور و بر اساس صحبتهای قبلی باب یاد گرفته است. مشاهدات مساله شرح فعالیتهایی است که باب در انتهای هر روز به آلیس میگوید.
حالا تصور کنید الان آلیس میخواهد به باب زنگ بزند و میخواهد بداند او خانه است (که مثلاً به تلفنش زنگ بزند) یا بیرون از خانه؟ (که مثلاً به موبایلش زنگ بزند)
پس، اینجا هم همان مشکل را داریم. الان باب بالاخره در خانه است یا بیرون؟ (kErEm یا kArAm یا...؟)
مسأله بالا توسط الگوریتم آقای مارکوف به صورت زیر مدل میشود:

حالات کلی: بارانی یا آفتابی بودن هوا
مشاهدات: قدم زدن، خرید کردن، تمیز کردن خانه
احتمالات آغازین (یعنی احتمالاتی که آلیس به مرور و طی مدتها صحبت یاد گرفته): به احتمال ۶۰ درصد هوای محل زندگی باب بارانی است و به احتمال ۴۰ درصد آفتابی.
احتمال انتقال از یک حالت به حالت دیگر: اگر دیشب باب گفته باشد که هوا بارانی است، به احتمال ۷۰ درصد امروز نیز بارانی است و به احتمال ۳۰ درصد آفتابی است و اگر دیشب گفته باشد که هوا آفتابی است، به احتمال ۴۰ درصد امروز آنجا بارانی است و به احتمال ۶۰ درصد همچنان آفتابی است...
احتمال بروز یک کار: اگر بارانی باشد به احتمال ۱۰ درصد باب بیرون قدم میزند، به احتمال ۴۰ درصد خرید میکند و به احتمال ۵۰ درصد خانه است و خانه را تمیز میکند. و اگر هوا آفتابی باشد به احتمال ۶۰ درصد قدم میزند، به احتمال ۳۰ درصد خرید است و به احتمال ۱۰ درصد در حال تمیز کردن خانه.
این مدل را میشود به صورت گراف زیر نشان داد، خوب به آن دقت کنید:

این نوع گرافها را دانشجویان رشته کامپیوتر در درس «نظریه زبانها و ماشینها» یا «ساختمانهای گسسته» و... دیدهاند.
حالا میتوانید راحتتر پاسخ بدهید: آلیس میخواهد به باب زنگ بزند، دیشب باب گفته هوا آنجا بارانی بوده. به نظر شما الان باب در حال انجام چه کاری است؟
پاسخ: نگاه کنید به حالت یا State یا همان دایرهی Rainy، یالهایی که عدد بیشتری دارند را دنبال کنید... به احتمال ۷۰ درصد به خودش میرود (یعنی وقتی گفته دیشب بارانی بوده به احتمال ۷۰ درصد امروز هم بارانی است) و به احتمال ۵۰ درصد به Clean میرود، پس او در حال نظافت و در خانه است...
***
پس، برای اینکه ما بفهمیم کلمه «کرم» را kErEm تلفظ کنیم یا kArAm یا kErm... نیاز به چنین گرافی داریم که از طریق مدل مارکوف به دست میآید.
یعنی به طور ساده، ما باید بدانیم کلمه «کرم» در کنار کلمات مختلف، کدام تلفظش را به خودش میگیرد؟ مثلاً: اگر کنار کلمه «مادر» بود، به احتمال ۹۰ درصد kErEm تلفظ میشود و به احتمال ۵ درصد kArAm به احتمال ۳ درصد kErm و به احتمال ۲ درصد kOrOm
یعنی یک دیتابیس حاوی کلمات مختلف یک زبان و اینکه اگر کنار هر کلمه دیگر بودند کدام تلفظشان را به خود میگیرند لازم است!
میدانید این چه دیتابیس بزرگی میشود؟ مثلاً در مورد زبان فارسی، باید تمام کلمات فارسی را تک به تک با تمام کلمات دیگر، احتمال انواع تلفظشان را بگویید!! یعنی n به توان n ضرب در تعداد تلفظهای هر کلمه!!!!
طبیعتاً چنین چیزی در نگاه اول محال است! اما خوب، میشود این درخت بزرگ را هرس کرد و زائدها را حذف کرد که این خودش یک رساله دکتراست!!
و یا میتوان در سادهترین حالت، مانند آن دیتابیس همشهری، از ۱۱ سال مطالب روزنامه همشهری یک دیتابیس ساخت و توسط انسان، تعداد تکرار هر کلمه (بسامد کلمه) با تلفظهای مختلف را به دست آورد...
نمایی از دیتابیس همشهری که در پارسخوان به کار رفته و نشان میدهد که تلفظ kArAm بیشترین بسامد را دارد... (پس متوجه میشوید که ما در پارسخوان با توجه به بسامد کلماتی که چند تلفظ دارند، کرم را همیشه kArAm میخوانیم. درست است که ممکن است خیلی از اوقات غلط بخواند اما حداقل در اکثر مواقع درست میخواند... دقت کنید که ممکن است آلیس یعنی یک انسان هم طبق گراف بالا به این نتیجه برسد که باب در حال تمیز کردن خانه است اما زنگ بزند و ببیند استثنائاً او در این لحظه حتی در هوای بارانی برای خرید رفته... پس همیشه تا دنیا دنیاست احتمال خطا وجود دارد، ما دنبا این هستیم که کمتر خطا کنیم...)
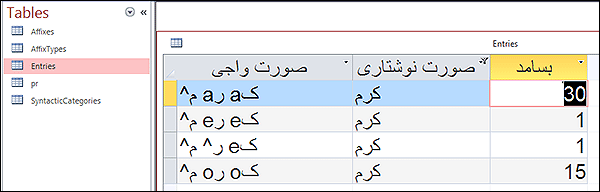
و یا میشود کار را از این حالت ساده، کمی بهبود بخشید و بر روی یک مجموعه مقالات (مثل همان مقالات روزنامه همشهری) تحلیل کرد که هر کلمه (مثلاً کلمه کرم) در این ۱۱ سال در کنار چه کلمات دیگری قرار گرفت و چطور تلفظ شد. (یعنی مجموعه را کوچکتر کرد تا بینهایت نشود) بعد نتیجه این تحلیلها را به نرمافزار داد که نرمافزار یاد بگیرد که هر کلمه در کنار کلمات دیگر چطور تلفظ میشود، سپس انتظار تلفظ بهتر داشت...
که البته این نیاز دارد که ابتدا نرم افزاری طراحی شود که صدها و چه بسا هزاران مقاله را از اینترنت با خزیدن در سایتها جمع کند و بر اساس کلمات دستهبندی کند و بعد از اینکه آن دیتابیس بزرگ ایجاد شد، کلمات را یک به یک به یک انسان نشان دهد و چند کلمه قبل و بعد را هم نشان دهد و در خود نگه دارد و سپس بخواهد که انسان انتخاب کند که کدام تلفظ در این متن صحیح است... (همین نرم افزار که یک ابزار جانبی به حساب میآید، خودش یک رساله دکترا میشود!!)
کاربردهای مدل مخفی مارکوف:
این مدل در زمینههای بسیار زیادی کاربرد دارد:
- تبدیل گفتار به صدا (تشخیص گفتار):
تصور کنید شما در حال خواندن یک متن برای یک نرم افزار هستید که او آنرا تایپ کند. اگر تلفظ یک کلمه شبیه یک کلمه دیگر باشد مثلاً میگویید: Important Object نرم افزار ممکن است Import an Object بشنود... چطور تشخیص دهد که کدام منظور شما بوده؟ با مدل مخفی ماکوف و چیزهایی که قبلاً یادش دادهاید...
- تشخیص چهره:
مثلاً فکر کنید یک نرم افزار تشخیص چهره، فاصله بین دو مردمک چشم را ملاک شناسایی قرار دهد. اگر برای دو نفر از افراد یک سازمان این فاصله یکسان باشد، کدام یکی الان جلو دستگاه ایستاده؟ با توجه به دانستههای دیگر میشود فهمید...
- ترجمه ماشینی:
همه با Google Translate کار کردهاند و میدانند که گاهی چقدر ضایع ترجمه میکند! دلیل؟ هنوز دیتابیس مربوط به مدل مخفی مارکوف گوگل کامل نشده. به همین دلیل است که گوگل، Community Help را راهاندازی کرده و از شما انسانها خواسته به مرور به آن نرم افزار یاد بدهید که وقتی فلان کلمه کنار فلان کلمه قرار میگیرد ترجمه اش چه میشود؟
- تایپ کشیدنی:
اگر میدانید تایپ کشیدنی چیست، همین حالا تست کنید: سعی کنید کلمه «سلام» را با تایپ کشیدنی تایپ کنید؛ خواهید دید که «سلام» تشخیص داده میشود. حالا آن را پاک کنید و دوباره سعی کنید «سلام» بنویسید، این بار یاد گرفته که کلمه قبلی احتمالاْ اشتباه تشخیص داده شده و به سراغ کلمه بعدی که در همین مسیر قرار دارد میرود؛ یعنی «سیم» و...
و صدها کاربرد دیگر...
حالا فکر میکنید پارسخوان ۲ (پارسخوان هوشمندتر+...) در راه است یا خیر؟ :)
موفق باشید؛
حمید رضا نیرومند





















 Hamid:
Hamid: